Unlocking Generative AI: A Detailed Walkthrough
Welcome to this deep dive into Generative AI. We're going to move beyond the buzzwords and break down the core concepts one by one, using simple analogies to explain how this technology truly works. Let's walk through the fundamentals, from the big picture to the nuts and bolts.
Section 1: What is GenAI? (The Calculator vs. The Storyteller)
First, what is Generative AI, or "GenAI"?
The Definition (Simplified):
Generative AI is a type of Artificial Intelligence that can create new things (like text, images, code, or music) instead of just analyzing existing data.
Think of it as a creative assistant that has been trained on a huge amount of information.
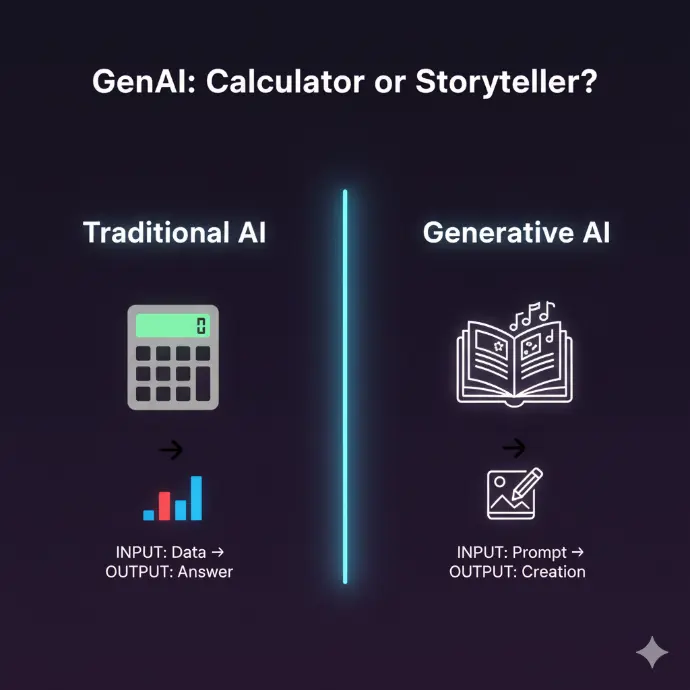
The Analogy: Calculator vs. Storyteller
This is the simplest way to understand the difference:
Traditional AI is like a Calculator: It's brilliant at a specific task. You give it a problem (like "predict next month's sales"), and it analyzes the data to give you an answer.
Generative AI is like a Storyteller: It can take a simple prompt (like "a story about a robot who finds a flower") and create something entirely new and original on its own.
Section 2: Traditional AI vs. GenAI (The Two Chefs)
Let's deepen that contrast with another analogy: The Two Chefs.
👨🍳 Chef ML (Traditional AI/ML):
This chef needs a specific recipe to cook. He is trained for one narrow task, like "predicting house prices." He works best with numbers and structured tasks. If you ask him to make something outside his recipe book (like a "fusion sushi pizza"), he fails. He can't invent.
🧑🎨 Chef GenAI (Generative AI):
This chef has read millions of recipes from all over the world. He understands the principles of cooking. You can ask him for a "fusion sushi pizza," and he will creatively combine his knowledge to invent a new dish for you.
This ability to create and invent, not just analyze, is the core of Generative AI.
Section 3: The "How" - Foundational Models, Pre-training & Fine-tuning
So, how do we build this "Creative Chef"? The process involves two key concepts: Foundational Models and the "schooling" they go through.
Part A: What is a Foundational Model? (The LEGO Box)
A Foundational Model is the "big box of pre-built pieces."
Instead of building a new car from scratch every single time (melting plastic, molding bricks), you get a giant box of all-purpose LEGO pieces. You can then use these same pieces as a foundation to build anything: a car, a house, or a spaceship.
A Foundational Model is a very large, general-purpose AI, trained on a vast range of data, that can be adapted to many different tasks.
This "LEGO box" isn't just for one thing. We have foundational models for:
Text: GPT (Generative Pre-trained Transformer)
Images: Stable Diffusion
Audio: Whisper (Speech-to-Text)
Part B: The "Schooling" Analogy (Pre-training vs. Fine-tuning)
This is the most important part. How does a model get so smart? It "goes to school," just like in your hand-drawn diagram.
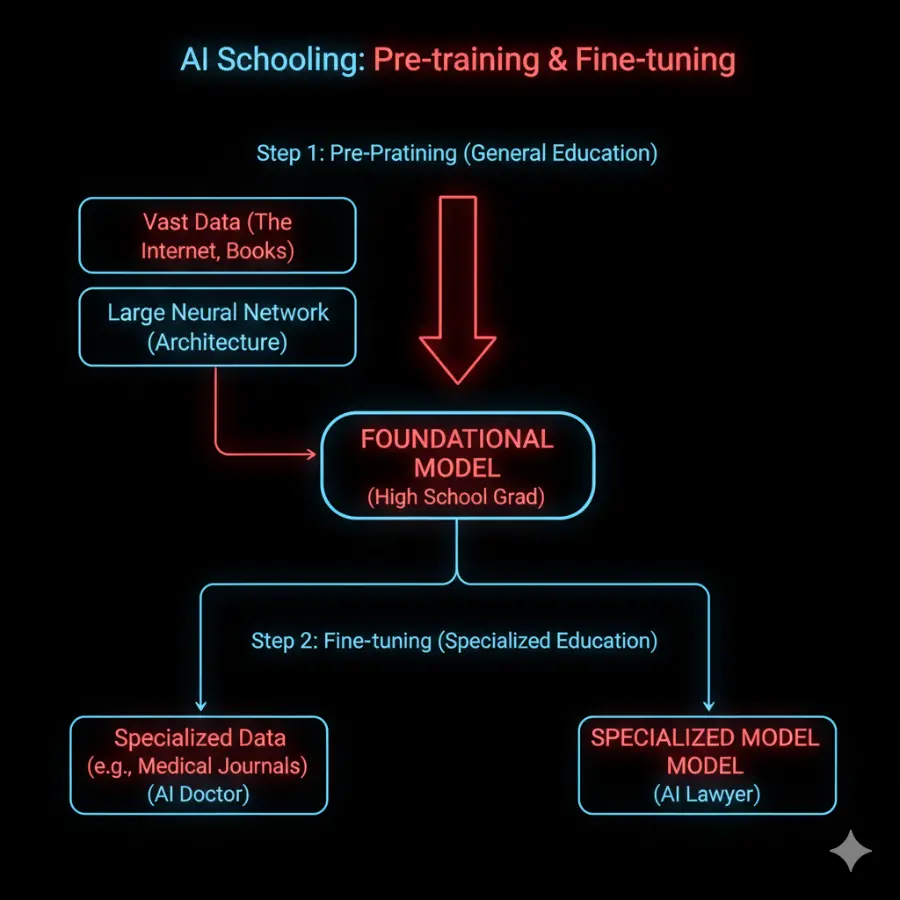
1. Pre-training (General Education: School -> High School)
This is the first and biggest step. We take a brand-new model (the "Architecture," or the "child") and send it to "school." This means we "pre-train" it by feeding it a massive, general-purpose dataset—like a huge chunk of the internet, all of Wikipedia, and thousands of books.
Just like a student in High School, the model isn't studying for one specific job. It's learning general knowledge:
How to read and write (grammar, language structure)
Basic facts about the world (history, science)
How to reason and connect ideas
The result of this "pre-training" is a Foundational Model. It's like a smart high school graduate: it has a vast amount of general knowledge but isn't a specialist... yet.
2. Fine-tuning (Specialized Education: University -> Career)
Once we have our "high school grad" (the FoundationalModel), we can "fine-tune" it for a specific job. This is like sending it to university to get a specialized degree.
We take the general-purpose model and train it again, but this time on a much smaller, specialized dataset.
Want an AI for Engineering? Fine-tune it on engineering textbooks and technical diagrams.
Want an AI for Medical advice? Fine-tune it on medical journals and research papers.
Want an AI for Law? Fine-tune it on legal documents and case histories.
Want an AI for Business? Fine-tune it on financial reports.
This two-step process (Pre-training + Fine-tuning) is incredibly efficient. We don't have to build a new AI from scratch for every task. We build one massive "Foundational Model" and then "fine-tune" it for 100s of different, specialized applications.
Section 4: The "Magic" - What is a Transformer?
For decades, AI struggled with one big thing: context.
The Storytelling Approach:
Imagine reading a novel, but you can only remember the last 5 words you read. You'd be instantly lost! That's how older AI models worked. They couldn't hold on to long-term context.
The Breakthrough: "Attention"
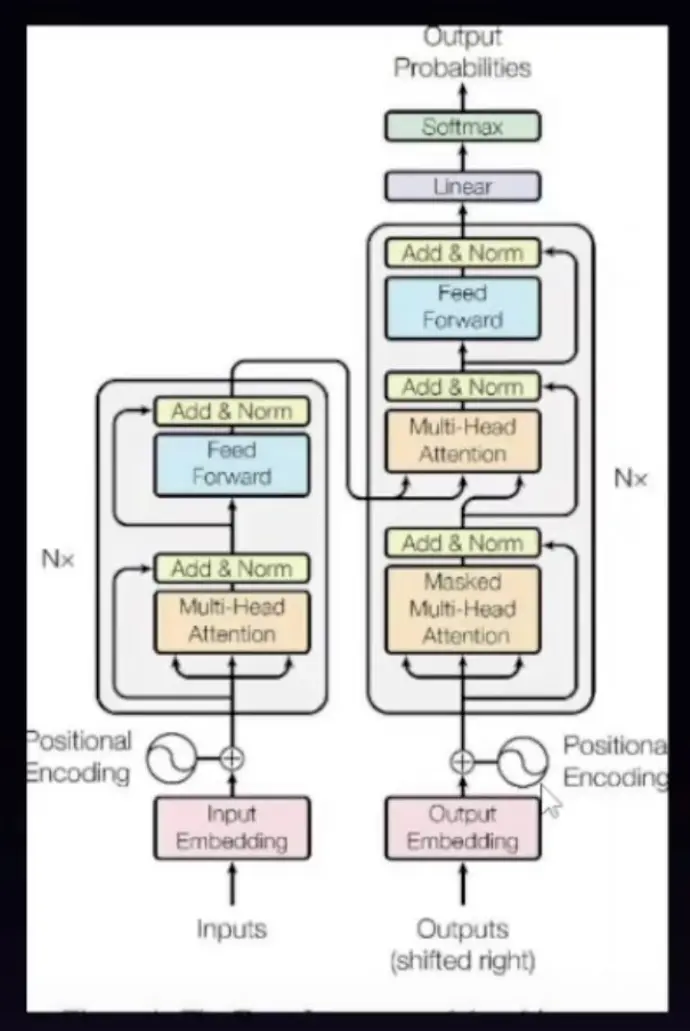
In 2017, the "Transformer" architecture was introduced. It gave AI a game-changing skill: Attention.
Instead of just looking at a few words, a Transformer can look at all the words in a sentence at once and decide which ones are most important to each other.

Example:
In the sentence: "The cat sat on the mat because it was tired."
An old model might get confused. Does "it" refer to the mat?
A Transformer uses "attention" to know that "it" refers to the "cat," not the "mat."
That ability to understand context is the magic that makes modern GenAI feel so human.
Section 5: The "Family Tree" (Transformers vs. BERT)
This new "Transformer" idea was so powerful that it spawned a whole family of new models. You'll often hear "Transformer" and "BERT" used together. What's the difference?
The Analogy: Engine vs. Car
This is the simplest way to think about it:
Transformers = A powerful new engine design.
BERT = A specific, famous car built using that engine.
Or, another way:
Transformers = The general architecture (like the invention of electricity).
BERT = A specific model built using that architecture (like the first light bulb).
What makes BERT special?
BERT (Bidirectional Encoder Representations from Transformers) was a famous model from Google that used this new Transformer architecture.
Its specialty was understanding context by reading sentences in both directions at once (left-to-right and right-to-left).
Example:
When BERT sees the word "bank," it looks at all the surrounding words to figure out:
Are we talking about a money bank? ("I need to deposit this check at the bank.")
Or a river bank? ("We had a picnic on the bank of the river.")
This deep contextual understanding, all powered by the Transformer architecture, is what makes tools like Google Search (which uses BERT) so effective.
## Conclusion
And there you have it! A complete walkthrough of Generative AI.
You know it's a "Creative Storyteller," not just a "Calculator." You know it's built on "Foundational Models" (like LEGOs) that are given a "High School" education (Pre-training) and then sent to "University" (Fine-tuning). And you know the magic behind it all is the "Transformer" architecture and its "Attention" mechanism.
#GenerativeAI #AI #ArtificialIntelligence #MachineLearning #TechExplained #Transformers #BERT #FoundationalModels #LLM #Pretraining #Finetuning #StableDiffusion #WhisperAI #OpenAI #TechSimplified #BusinessInnovation #DataScience